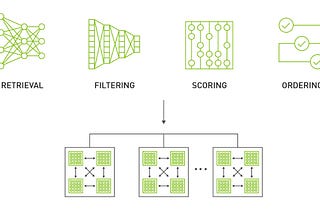
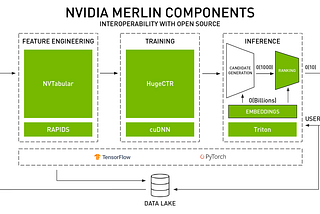
Radek OsmulskiinNVIDIA MerlinHow to preprocess data using NVTabular on multiple GPUs?Multi-GPU machines are becoming much more common. Training deep learning models across multiple-GPUs is something that is often discussed.Apr 13, 2023Apr 13, 2023
Radek OsmulskiinNVIDIA MerlinLearn how Meta, Alibaba, ASOS, and Kuaishou Technology are delivering recommendations at scale (at…Over the last couple of months, the Merlin team has been all about aligning the features of our software with customer needs and developing…Mar 8, 2023Mar 8, 2023
Radek OsmulskiinNVIDIA MerlinHow to run Merlin on Google ColabColab provides access to GPUs for new learners and enables experienced practitioners an easy way to experiment with the Merlin recommender…Jan 24, 20234Jan 24, 20234
Radek OsmulskiinNVIDIA MerlinTransformers, multi-GPU, HPO, and more are here for Recommender Models in the 22.11We recently released a new version of the Merlin Framework! We added a couple of features that can help you train better models faster and…Dec 1, 2022Dec 1, 2022
Radek OsmulskiinNVIDIA MerlinBuilding a Diverse Models Ensemble for Fashion Session-Based Recommendation for RecSys2022…A team from NVIDIA took part in the recent ACM RecSys 2022 Challenge. The team consisted of several NVIDIA Kaggle Grandmasters and…Sep 20, 20221Sep 20, 20221
Radek OsmulskiinNVIDIA MerlinExploring Production Ready Recommender Systems with Merlinby Radek Osmulski and Benedikt SchiffererJul 5, 20221Jul 5, 20221
Radek OsmulskiinNVIDIA MerlinScale faster with less code using Two Tower with Merlinby Radek Osmulski, Benedikt Schifferer, Ronay Ak and Gabriel MoreiraJun 21, 20223Jun 21, 20223
Radek OsmulskiHow to build a Deep Learning system that will answer questions about the Harry Potter universe?To achieve our goal, which is to build a Q&A system that will answer questions about the Harry Potter universe, we will use NVIDIA Riva and…Aug 6, 2021Aug 6, 2021
Radek OsmulskiHow to use the power of the community to learn fasterCommunity is the most powerful force behind online learning. It is the reason why MOOCs have a limited impact and tight-knit communities…May 21, 2021May 21, 2021
Radek OsmulskiinThe StartupGoing From Not Being Able to Code to Deep Learning HeroA detailed plan based on experienceJan 14, 2021Jan 14, 2021